Neuroendocrine tumours (NETs) are relatively rare malignancies with diverse biology. They originate from neuroendocrine tissue and can release a variety of functional biochemicals creating neoplastic syndromes that are difficult to manage. Although 5-year survival rates are favourable with early diagnoses, the majority of patients present with metastatic disease and frequently progress on treatment. There is thus an unmet clinical need to understand disease dynamics and identify novel therapeutic options.
This need is increasingly being addressed through computational modelling and artificial intelligence (AI). This supports studies ranging from identifying cells in the tumour microenvironment to biomarker identification and virtual experiments for optimising therapies.
Here, we introduce major categories of computational methods applied in research into NETs, including cutting-edge technologies, such as digital twins and the use of large language models (LLMs).
KNOWLEDGE-DRIVEN MODELLING: MECHANISTIC MODELLING
Computational mechanistic models describe dynamic processes by encoding biological and clinical knowledge via mathematical relationships. Examples of these techniques include ordinary differential equations to simulate tumour growth over time, quantitative systems pharmacology frameworks to integrate drug effects, drug distribution and molecular data, and agent‑based models to capture cell–microenvironment interactions and spatial heterogeneity.
In contrast to data-driven models (see below), mechanistic models can provide explanations for biological processes.1 These models often offer clear interpretability and safe extrapolation beyond training data, making them excellent at hypothesis testing to guide future experiments. Furthermore, these models can be combined with data-driven models, taking advantage of the strengths of both methods.2

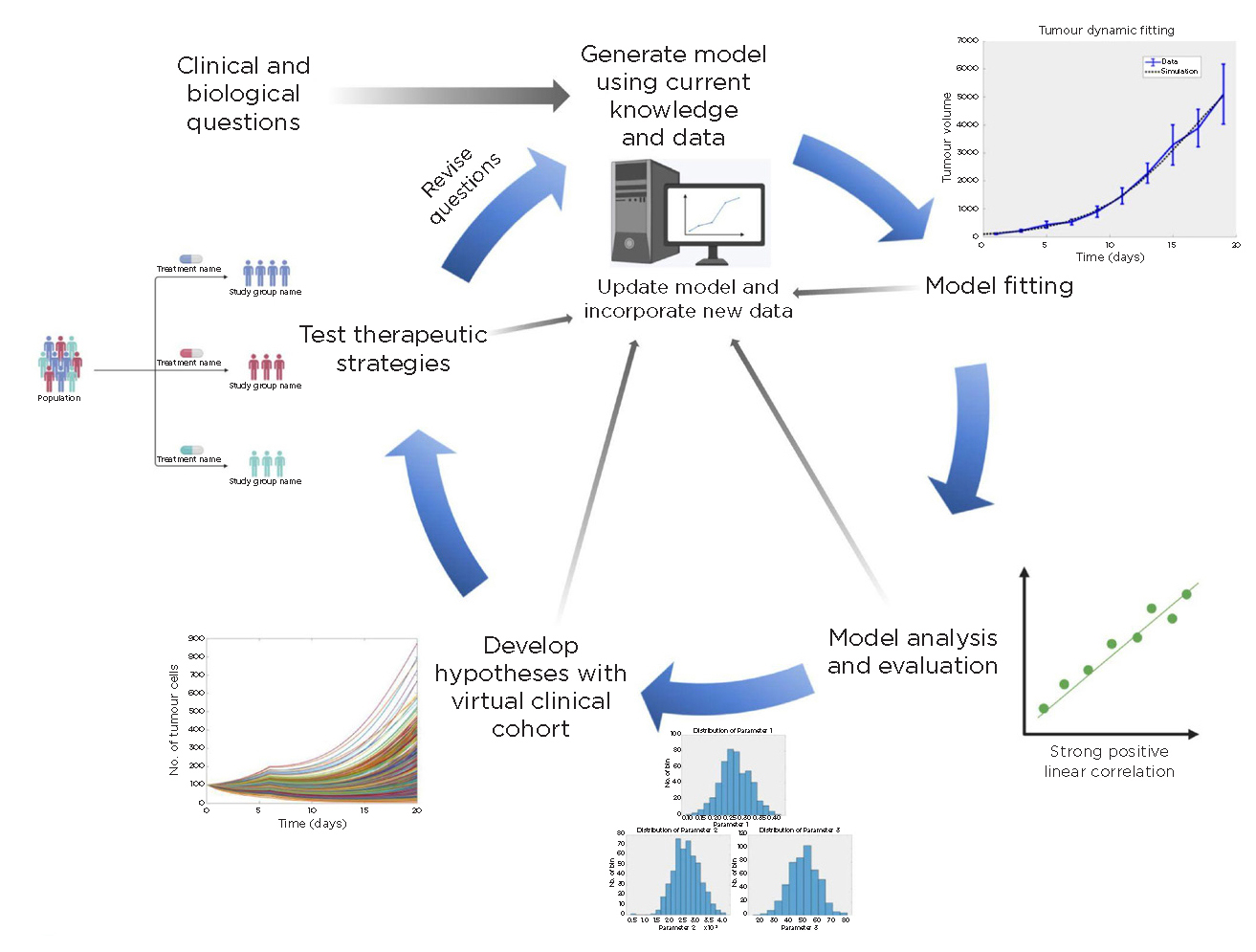
The multidisciplinary cycle of a computational model, illustrated with mechanistic modelling, spans the pathway from bench to bedside. Reproduced under CC BY 4.0 licence from Metzcar et al.1 ©2020 The Authors
DATA-DRIVEN MODELLING
Data-driven methods can be used to (1) find structure within datasets and (2) predict values or categorise and label data. The former is done using unsupervised learning, while supervised learning techniques are used for the latter. Studies may combine both unsupervised learning to reduce the dimensionality of imaging or omics data then supervised models to classify an image or predict prognosis.
Within each broad category are methods that stress interpretability and uncertainty quantification of model parameters (often called statistical learning, e.g. linear regression or Bayesian methods). They maintain parameter interpretability and can quantify uncertainty.
Alternatively, there are machine learning (ML) approaches, such as neural networks and random forests, which can capture complex relationships accurately at the expense of interpretability and transparency.
Finally, data-driven models also include semi‑/self‑supervised techniques that are well-suited to unlabelled data, transfer learning with pretrained models, and more.
EXAMPLES
Below, we provide brief examples, noting that many more examples and techniques exist than are provided. We invite the interested reader to pursue this further.
Finding structure – unsupervised learning
Tools like principal component analysis (PCA), uniform manifold approximation and projection (UMAP) and t-distributed stochastic neighbour embedding (t‑SNE) collapse thousands of radiomic or transcriptomic features to a small number of axes before clustering similar samples. This can reveal important and informative cell, tumour or patient subgroups without requiring the data to be pre-labelled.
Recent single‑cell studies on small‑intestinal NETs used UMAPs to compress thousands of transcripts per cell, finding high-functional tumour microenvironment heterogeneity across patients, while other studies clustered expression data using PCA and t-SNE.3,4 Using these methods on spatial transcriptomics enables the mapping of clusters back onto tissue sections, linking cell states to their microanatomic context.5
Additional applications of unsupervised learning include generating synthetic data (based in autoencoders) and feature extraction (PCA and others).
Prediction – supervised learning
When an outcome (e.g. tumour grade, time to progression, patient response) is known, researchers can develop predictive models. Two recent studies used deep‑learning pipelines to analyse surgical samples: one automated Ki‑67 scoring on digital slides, potentially enabling additional sampling of this critical prognostic value,6 with the second predicting metastatic risk.7
Other general examples of supervised learning include penalised Cox regression for survival analysis and prediction of outcomes from radiomics data.
MACHINE LEARNING CAVEATS
Machine learning includes a set of powerful methods, but they often lack transparency and explainability. This is especially crucial in clinical decision making. Understanding how ML models, especially neural networks, make decisions constitutes its own important sub-area of research in ML known as explainable AI.8 Of course, all of these methods have the usual caveat that correlation is not causality.
NEXT ADVANCES: LARGE LANGUAGE MODELS
'Combining real-world data with mechanistic understanding via hybrid methods, digital twins allow researchers to simulate tumour trajectories and treatments in silico.'
Finally, LLMs such as DeepSeek, GPT-4o (as in Chat-GPT) and Llama 4 are fundamentally changing research. They can be used to summarise articles, extract structured information from electronic health records and even potentially help in the clinic.
A very recent example assessed LLM responses to NET‑related questions. It found clear answers were provided, but therapy-related questions scored poorly, highlighting both the potential of LLMs and the need for clinician oversight and model improvement.9
NEXT ADVANCES: DIGITAL TWINS
Digital twins are patient‑specific virtual models that update as new laboratory results, imaging and biomarkers arrive.10 Combining real-world data with mechanistic understanding via hybrid methods, digital twins allow researchers to simulate tumour trajectories and treatments in silico. These patient-specific models can inform the next steps before returning to the clinic or lab.
While not yet deployed as routine research and clinical tools, they have the potential to impact all aspects of translational and clinical research. Additionally, combining LLM‑driven knowledge extraction with digital twins could create adaptive research workflows that link rapid evidence gathering to mechanistic exploration.
RESEARCH IMPACT AND LOOKING AHEAD
Bringing together mechanistic models and data‑driven methods has the potential to reshape the research toolkit for NETs. As these approaches mature, transparent reporting, validation against experimental or clinical data, and multidisciplinary teams are essential. Together, they can accelerate biomarker discovery, deepen fundamental understanding and power in silico experiments that bridge laboratory and clinical research, ultimately increasing clinical trial success.
With these computational methods, we can link diverse data sets such as clinical summaries, repeat imaging studies, pathologic features and time-series laboratory values into a dynamic digital twin, bringing us closer to truly personalised therapy.
Finally, we hope this feature inspires collaboration across the quantitative, biological and clinical sciences, producing a virtuous cycle of hypothesis generation, testing and refinement (see Figure), and accelerates the path from discovery to real-world solutions in the endocrine oncology community and beyond.
JOHN METZCAR
Therapy Modeling and Design Center, University of Minnesota– Twin Cities, Minneapolis, MN, USA
REBECCA A BEKKER
Alfred E Mann Department of Biomedical Engineering, University of Southern California, Los Angeles, CA, USA
VINAY M PAI
Chief Technology Officer, Health Tequity LLC, Berkeley, CA, USA
JUN PARK
Department of Endocrinology, Kaiser Permanente, South Sacramento, CA, USA
REFERENCES
1. Metzcar J et al. 2025 Endocrine Oncology https://doi.org/10.1530/eo-24-0025.
2. Metzcar J et al. 2024 Frontiers in Immunology https://doi.org/10.3389/fimmu.2024.1363144.
3. Somech E et al. 2025 eLife https://doi.org/10.7554/eLife.101153.
4. Scott AT et al. 2020 Clinical Cancer Research https://doi.org/10.1158/1078-0432.CCR-19-2884.
5. Yogo A et al. 2025 Endocrine Abstracts https://doi.org/10.1530/endoabs.108.b2.
6. Yücel Z et al. 2024 Medical & Biological Engineering & Computing https://doi.org/10.1007/s11517-024-03045-8.
7. Klimov S et al. 2021 Frontiers in Oncology https://doi.org/10.3389/fonc.2020.593211.
8. Roscher R et al. 2020 IEEE Access https://doi.org/10.1109/ACCESS.2020.2976199.
9. Panzuto F et al. 2025 Endocrine https://doi.org/10.1007/s12020-025-04294-9.
10. Sager S 2023 Journal of Cancer Research & Clinical Oncology https://doi.org/10.1007/s00432-023-04633-1.



{kind=link}
{kind=link}